Personal tools
Document Actions
PGHPF Compiler User's Guide - 5 Data Distribution
 << " border=0>
<< " border=0>
 > " border=0>
> " border=0>





5 Data Distribution
- 5.1 Run-time Model - Overview
- 5.2 HPF Data Distribution
- 5.3 InterProcedural Analysis (IPA) Overview
- 5.4 Static Data Initialization
This chapter describes some of the techniques the HPF language and the PGHPF compiler use to handle data distribution among processors on a parallel system. This chapter also describes some data distribution limitations for the current version of PGHPF. The PGHPF compiler distributes data and generates necessary communications with the assistance of the PGHPF runtime library. Depending on the data type, distribution specification, and alignment specification, as well as each computation's required data access, data is communicated for a particular expression involving some computation. Data distribution is based on the data layout specified in the HPF program, the design of the parallel computer system and the layout and number of processors used. Some mapping of data to processors is specified by the programmer, other mapping is determined by the compiler.
5.1 Run-time Model - Overview
The PGHPF compiler targets an SPMD programming model. In the SPMD model, each processor executes the same program, but operates on different data. This is implemented by loading the same program image into each processor. Each processor then allocates and operates on its own local portion of distributed arrays, according to the distributions, array sizes and number of processors as determined at runtime. Special attention is required to address the unique communication characteristics of many parallel systems. The PGHPF Runtime library handles HPF data distribution tasks in a generic manner so that HPF programs will work on distributed memory and shared memory systems (some parallel systems use shared memory others use distributed memory, there are also hybrid systems. Lower levels of the PGHPF runtime library are customized for different parallel architectures). Figure 5-1, "Distributed Memory Parallel System", shows a conceptual view of a parallel system running an HPF program.
The PGHPF runtime library takes into account the communications to be performed and is optimized at two levels, the transport independent level where efficient communications are generated based on the type and pattern of data access for computations, and at the transport dependent level where the runtime library's communication is performed using a communications mechanism and the system's hardware. To generate efficient code, data locality, parallelism, and communications must be managed by the compiler. This chapter describes the principles of data distribution that HPF and the PGHPF compiler use; the HPF programmer needs to be aware of some details of data distribution to generate efficient parallel code.
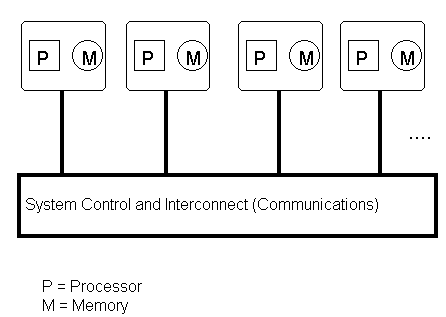
Figure 5-1 A Distributed Memory Parallel System
5.2 HPF Data Distribution
The data distribution phase of the PGHPF compiler has two important tasks that map data to a parallel system's memory and enable computations on that data:
- The compiler propagates an efficient data distribution for the program's variables.
- Each computation is partitioned according to the specified data distribution and non-local values are communicated, as necessary, for each computation.
The following sections describe these tasks in more detail.
5.2.1 Propagating Data Distribution
The PGHPF compiler distributes data for several classes of variables:
- User specified variables with a user specified distribution.
- Compiler-created temporary variables.
The compiler uses HPF directives as a guide for distributing the data that has a user specified distribution. Data without distribution directives is replicated across all processors. Compiler-created temporaries are distributed corresponding to their required usage.
Default Distribution
Using the compiler's default distribution, all unspecified data, data without an explicit HPF distribution, is replicated among the available processors. For example, if the integer array BARRAY is used in a program and no HPF directives are supplied for distributing or aligning BARRAY, the default distribution is used and BARRAY is replicated. PROG1 and PROG2 in Example 5-1 show the default distribution. In PROG1, the compiler generates code using the default distribution because BARRAY is specified without a distribution, PROG2 shows an equivalent user specified distribution where BARRAY is also replicated.
! distribution directives not supplied - replication PROG1 INTEGER BARRAY(100) !default distribution directives supplied - replication PROG2
INTEGER BARRAY(100) !HPF$ DISTRIBUTE BARRAY(*)
Example 5-1 A default distribution
Explicit HPF Distribution
As described in Chapters 4 and 5 of the High Performance Fortran Handbook, PGHPF distributes data according to the supplied HPF directives. The ALIGN and DISTRIBUTE directives allow data to be distributed over processors in a variety of patterns. For example, the following code represents a distribution where a computation is partitioned over the available processors. With the given ALIGN directive, this computation involves no communication.
REAL X(15), Y(16)
!HPF$ DISTRIBUTE Y(BLOCK)
!HPF$ ALIGN X(I) WITH Y(I+1)
FORALL(I=1:15) X(I)=Y(I+1)
The next example is very similar, but uses a CYCLIC distribution. A cyclic distribution divides data among processors in a round-robin fashion. A block distribution divides data into evenly distributed chunks (as evenly as possible) over the available processors. A cyclic distribution divides data over processors so that each processor gets one element from each group of n elements, where n is the number of processors.
Figure 5-2 shows block and cyclic distributions for a one dimensional array. Depending on the computation performed different data distributions may be advantageous. For this computation a CYCLIC distribution would involve communication for each element computed.
REAL X(15), Y(16)
!HPF$ DISTRIBUTE Y(CYCLIC)
!HPF$ ALIGN X(I) WITH Y(I+1)
FORALL(I=1:15) X(I)=Y(I+1)
In the next example, a similar distribution represents a computation that would be partitioned over the available processors, (for the example we call the processors processor one and processor two). Because of the alignment specified in these ALIGN and DISTRIBUTE directives, the computation involves communication since the value for Y(9) when I is 8 needs to be communicated to assign it to X(8). X(8) is stored on processor one and Y(9) is stored on processor two.
REAL X(15), Y(16)
!HPF$ DISTRIBUTE Y(BLOCK)
!HPF$ ALIGN X(I) WITH Y(I)
FORALL(I=1:15) X(I)=Y(I+1)
The following example shows an erroneous distribution that programmers should avoid. According to the HPF specification, the value of a dummy index variable, I in this example, must be valid for all subscript values possible for the data, X in this example. When the ALIGN dummy index ranges for all possible value of I, 1 to 16 for this example, there would be an invalid access to the value Y(16+1). This error will give a runtime error.
REAL X(16), Y(16)
!HPF$ DISTRIBUTE Y(BLOCK)
!HPF$ ALIGN X(I) WITH Y(I+1)
FORALL(I=1:15) X(I)=Y(I+1)
This code produces the following runtime error message :
0: set_aligment: invalid alignment 1: set_aligment: invalid alignment
For more details on different data distributions and examples showing more HPF data mapping directives, refer to Chapter 4 of The High Performance Fortran Handbook.
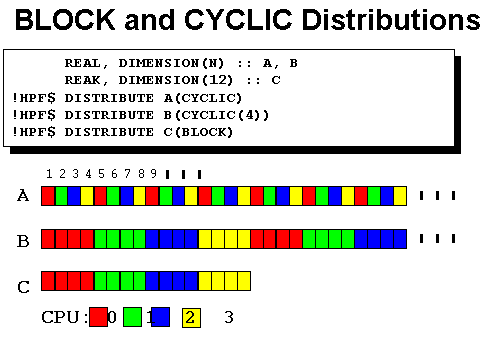
Figure 5-2 Block and Cyclic Distribution
Distributing Allocatable Arrays
Allocatable arrays can be distributed in a manner similar to standard arrays (arrays without the ALLOCATABLE attribute). The directives that determine the distribution and alignment of an allocatable array are evaluated on entry to the allocatable array's scoping unit and are used throughout the scoping unit for creation of the array, although the arrays may later be realigned or redistributed.
Using allocatable arrays, it is important to keep in mind that an object that is being aligned with another object must exist. Thus, in the following example, the order of the ALLOCATE statements is correct; however, an incorrect ordering, when B is allocated before A, will produce a runtime alignment error.
0: TEMPLATE: invalid align-target descriptor
REAL, ALLOCATABLE:: A(:), B(:)
!HPF$ ALIGN B(I) WITH A(I)
!HPF$ DISTRIBUTE A(BLOCK)
ALLOCATE (A(16))
ALLOCATE (B(16))
Distribution of Procedure Arguments
The distribution of procedure arguments is described in detail in Chapter 5 of The High Performance Fortran Handbook. An important principle for HPF is the alignment of an argument when a procedure is called is maintained when the procedure returns, regardless of the distribution of the argument within the procedure. Thus, the compiler may need to redistribute the variable upon entry to the procedure, and when exiting the procedure.
Distribution of Compiler Created Temporaries
The PGHPF compiler creates a distribution for compiler-created temporary variables. Compiler-created temporaries are distributed corresponding to the required usage. The compiler creates temporaries for several reasons:
- When an array section is passed to a subroutine, a temporary is created to hold the value of the array. Normally this does not happen unless the array has to be redistributed.
- When an array-valued function is used in an expression, a temporary is created to hold the return value of the function.
- When a scalarized FORALL carries a dependence, a temporary is created to hold the value of the right hand side (FORALL statements are scalarized by converting them to a DO statement).
- When a transformational function is referenced within a FORALL, a temporary is created to hold the result of the transformational function.
- Sometimes the compiler's communications implementation requires creation of temporaries.
Distribution of temporaries and user variables are performed identically; the use of temporaries is transparent from the HPF programmer's point of view (the temporaries are visible in the intermediate code).
The algorithm PGHPF uses to determine distribution of temporaries takes the statement in which the temporary is used into account. Temporaries are allocated before the statement in which they are used and deallocated immediately after that statement. For example, an array assignment:
INTEGER, DIMENSION(100,100):: A,B,C,D
A = SUM(B) + MATMUL(C,D)
would generate intermediate code using a temporary array.
For this class of temporaries, distribution is based on the usage of the temporary. If a temporary is used as the argument to an intrinsic, the compiler tries to determine the distribution based on the other intrinsic arguments. Otherwise, it tries to assign a distribution based on the value assigned to the temporary. Otherwise, the temporary is replicated across all processors.
Numerous factors including array alignment, array distribution, array subsection usage and argument usage need to be taken into account in determining temporary distribution. For example, consider the following :
A(1:m:3) = SUM(B(1:n:2,:) + C(:,1:n:4), dim = 2)
The section of A is passed directly to the SUM intrinsic to receive the result. A temporary is needed to compute the argument to SUM. The distribution of that temporary has two possibly conflicting goals: minimize communication in the B+C expression, or minimize communication in the SUM computation and in the assignment to A.
5.2.2 Computation Partitioning
Computations are partitioned when PGHPF applies the owner-computes rule. This rule causes the computation to be partitioned according to the distribution of the assigned portion of the computation and involves localization based on the left-hand-side (lhs) of an array assignment statement.
The bounds of a FORALL statement are localized according to the array elements owned by the left-hand-side.
For BLOCK partitioned dimensions, the loop bounds are adjusted to index the slice of data owned by the current processor.
For CYCLIC partitioning, two loops are required. The outer loop iterates over the cycles of the data, and the inner loop iterates over the data items in the cycle.
5.3 InterProcedural Analysis (IPA) Overview
The PGHPF compiler has a InterProcedural Analysis (IPA) phase. Using the option -Mipa, the compiler checks routines across subroutine boundaries and reports a number of errors and warnings that will not be detected otherwise. Optimizations are performed across procedure boundaries when possible.
The format of this option is:
-Mipa=lib
- where lib is:
- the name of the IPA library directory to store the files generated and used in IPA program checking. The library directory is used to store information about procedure arguments and other data that is checked across routines. If the directory does not exist, the compiler will create it.
The IPA phase performs the following types of analysis:
- Interprocedural MOD analyses
- When a formal argument is not modified, it is treated as an
INTENT(IN) argument in the routine's callers.
- Interprocedural constant propagation
- When a formal argument has the same constant value at all its call sites,
the formal is replaced by the constant value in the routine.
- Interprocedural Propagation of alignments and distributions
- When all call sites have the same distribution for a formal argument, IPA
will change a !hpf$ inherit attribute to the actual distribution.
Moreover, if two formals with inherited distributions are aligned to each other
at all call sites, the dummy arguments will be treated as aligned in the
subprogram. Even if the caller and callee have the same alignment, the compiler
optimizes the code.
- Common block variable analysis
- The IPA phase eliminates the common block initialization code in routines if the common was initialized in the main program.
Once IPA checking is complete, the IPA lib directory will contain a number of files. It is the programmer's task to remove these files. If they are not removed they will remain in the directory and will be used in future compilations when the same lib directory is selected for the IPA phase (see the following subsections).
The IPA Phases
The compiler runs three phases to support Interprocedural Analysis. The command:
%pghpf -Mipa=lib source.hpf
is equivalent to running all three phases. The following subsections describe these phases.
phase 1 analysis
This phase analyzes each procedure and creates the following files. To run only this phase, use the -ca IPA option, for example: -Mipa=lib -ca source.hpf.
- source.ipa
- contains only the source file name. This can be used for makefile processing.
- lib
- this directory contains all of the IPA analysis files.
- lib/ipa.toc
- Contains one line for each subprogram or ENTRY statement in the program.
- lib/source.ipa
- contains a summary of each subprogram.
phase 2: propagation
This is the propagation phase which analyzes the entire program. To run only this phase, use the -cp IPA option, for example: -Mipa=lib -cp.
This phase creates the following files:
- lib/source.ipaout
- an IPA output file containing the results of interprocedural propagation to the corresponding routine. This phase will touch the file source.ipa if the IPA output information has changed since the last time IPA was run on this program. This makes the source.ipa file useful for makefile processing.
phase 3: inheriting
This compiles the routines in source.hpf and creates no new files. To run only this phase, include the .ipa source file on the command line, for example:
5.4 Static Data Initialization
Data that is distributed with a !HPF$ DISTRIBUTE directive, and initialized with a DATA statement is valid in PGHPF. A new option, -Mkeepstatic keeps the intermediate file which is normally removed by the compiler. This option has been added to the definition of -Mg, so that the intermediate file is retained when flags are set for debugging.
To support certain HPF features, including static data initialization, PGHPF now implements a prelink phase. If you are familiar with output from PGHPF using the -v option in PGHPF 2.2, this change will be very noticeable with newer PGHPF compilers, as a number of new prelink phases have been added to the compilation process. The prelinker collects the following information about the program being linked and generates a new subroutine (pghpf$static$init) to implement them:
- NAMELIST in a MODULE specification
- distributed arrays in MODULE
- distributed arrays in SAVE
- distributed arrays in COMMON
- data-initialized distributed arrays
Necessary information about the routines in source.hpf is saved by PGHPF in a file named source.d The prelinker reads the appropriate .d files to generate the initialization subroutine pghpf$static$init. If -Mkeepstatic is set, this subroutine is written to the file pghpf.prelink.f and saved.
Note
You will now see .d files along with .o files in your compilation directories. The information in the .d files is required for the PGHPF prelink phase.
- -Mnoprelink
- The prelink phase can be disabled by compiling with the compiler switch -Mnoprelink. Using the option -Mnoprelink, the following features will not work:
- NAMELIST in a MODULE specification
- distributed arrays in SAVE
- data-initialized distributed arrays
Additionally, with -Mnoprelink, distributed arrays in modules or common blocks will generate less efficient code.
A new option has been added to support variations with the prelink phase. The option, -W9, will pass switches to the prelink phase, but not to the regular Fortran compilation.
<< " border=0>
> " border=0>