Personal tools
Document Actions
1.2 Internationalization and Localization




Click on the banner to return to the user guide home page.
1.2 Internationalization and Localization
Computer users all over the world prefer to interact with their systems using their own local languages and cultural conventions. As a developer aiming for high international acceptance of your products, you need to provide users the flexibility for modifying output conventions to comply with local requirements, such as different currency and numeric representations. You must also provide the capability for translating interfaces and messages without necessitating many different language versions of your software.
Two processes that enhance software for worldwide use are internationalization and localization. Internationalization is the process of building into software the potential for worldwide use. It is the result of efforts by programmers and software designers during software development.
Internationalization requires that developers consciously design and implement software for adaptation to various languages and cultural conventions, and avoid hard-coding elements that can be localized, like screen positions and file names. For example, developers should never embed in their code any messages, prompts, or other kind of displayed text, but rather store the messages externally, so they can be translated and exchanged. A developer of internationalized software should never assume specific conventions for formatting numeric or monetary values, or for displaying date and time.
Localization is the process of actually adapting internationalized software to the needs of users in a particular geographical or cultural area. It includes translation of messages by software translators. It requires the creation and availabity of appropriate tables containing relevant local data for use in a given system. This typically is the function of system administrators, who build facilities for these functions into their operating systems . Users of internationalized software are involved in the process of localization in that they select the local conventions they prefer.
The Standard C++ Library offers a number of classes that support internationalization of your programs. We will describe them in detail in this chapter. Before we do, however, we would like to define some of the cultural conventions that impact software internationalization, and are supported by the programming languages C and C++ and their respective standard libraries. Of course, there are many issues outside our list that need to be addressed, like orientation, sizing and positioning of screen displays, vertical writing and printing, selection of font tables, handling international keyboards, and so on. But let us begin here.
1.2.1 Localizing Cultural Conventions
The need for localizing software arises from differences in cultural conventions. These differences involve: language itself; representation of numbers and currency; display of time and date; and ordering or sorting of characters and strings.
1.2.1.1 Language
Of course, language itself varies from country to country, and even within a country. Your program may require output messages in English, German, French, Italian, or any number of languages commonly used in the world today.
Languages may also differ in the alphabet they use. Examples of different languages with their respective alphabets are given below:

1.2.1.2 Numbers
The representation of numbers depends on local customs, which vary from country to country. For example, consider the radix character, the symbol used to separate the integer portion of a number from the fractional portion. In American English, this character is a period; in much of Europe, it is a comma. Conversely, the thousands separator that separates numbers larger than three digits is a comma in American English, and a period in much of Europe.
The convention for grouping digits also varies. In American English, digits are grouped by threes, but there are many other possibilities. In the example below, the same number is written as it would be locally in three different countries:
|
1,000,000.55 |
US |
|
1.000.000,55 |
Germany |
|
10,00,000.55 |
Nepal |
1.2.1.3 Currency
We are all aware that countries use different currencies. However, not everyone realizes the many different ways we can represent units of currency. For example, the symbol for a currency can vary. Here are two different ways of representing the same amount in US dollars:
|
$24.99 |
US |
|
USD 24.99 |
International currency symbol for the US |
The placement of the currency symbol varies for different currencies, too, appearing before, after, or even within the numeric value:

The format of negative currency values differs:

1.2.1.4 Time and Date
Local conventions also determine how time and date are displayed. Some countries use a 24-hour clock; others use a 12-hour clock. Names and abbreviations for days of the week and months of the year vary by language.
Customs dictate the ordering of the year, month, and day, as well as the separating delimiters for their numeric representation. To designate years, some regions use seasonal, astronomical, or historical criteria, instead of the Western Gregorian calendar system. For example, the official Japanese calendar is based on the year of reign of the current Emperor.
The following example shows short and long representations of the same date in different countries:
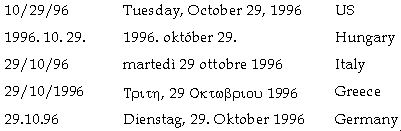
The following example shows different representations of the same time:
|
4:55 pm |
US time |
|
16:55 Uhr |
German time |
And the following example shows different representations of the same time:

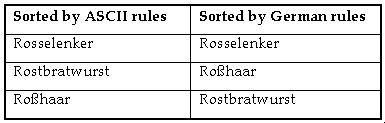
1.2.1.5 Ordering
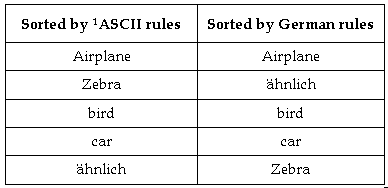
Languages may vary regarding collating sequence; that is, their rules for ordering or sorting characters or strings. The following example shows the same list of words ordered alphabetically by different collating sequences:
 [1]
[1]
The ASCII collation orders elements according to the numeric value of bytes, which does not meet the requirements of English language dictionary sorting. This is because lexicographical order sorts a after A and before B, whereas ASCII-based order sorts a after the entire set of uppercase letters.
The German alphabet sorts 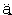 before b, whereas the ASCII order sorts an umlaut after all other letters.
before b, whereas the ASCII order sorts an umlaut after all other letters.
In addition to specifying the ordering of individual characters, some languages specify that certain groups of characters should be clustered and treated as a single character. The following example shows the difference this can make in an ordering:
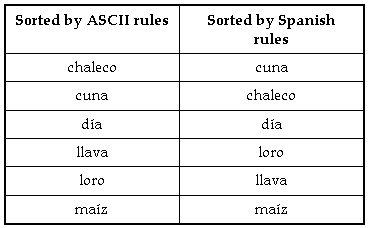
The word llava is sorted after loro and before 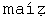 , because in Spanish ll is a digraph[2], i.e., it is treated as a single character that is sorted after l and before m. Similarly, the digraph ch in Spanish is treated as a single character to be sorted after c, but before d. Two characters that are paired and treated as a single character are referred to as a two-to-one character code pair.
, because in Spanish ll is a digraph[2], i.e., it is treated as a single character that is sorted after l and before m. Similarly, the digraph ch in Spanish is treated as a single character to be sorted after c, but before d. Two characters that are paired and treated as a single character are referred to as a two-to-one character code pair.
In other cases, one character is treated as if it were actually two characters. The German single character 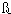 , called the sharp s, is treated as ss. This treatment makes a difference in the ordering, as shown in the example below:
, called the sharp s, is treated as ss. This treatment makes a difference in the ordering, as shown in the example below:
1.2.2 Character Encodings for Localizing Alphabets
We know that different languages can have different alphabets. The first step in localizing an alphabet is to find a way to represent, or encode, all its characters. In general, alphabets may have different character encodings.
The 7-bit ASCII codeset is the traditional code on UNIX systems.
The 8-bit codesets permit the processing of many Eastern and Western European, Middle Eastern, and Asian Languages. Some are strictly extensions of the 7-bit ASCII codeset; these include the 7-bit ASCII codes and additionally support 128-character codes beyond those of ASCII. Such extensions meet the needs of Western European users. To support languages that have completely different alphabets, such as Arabic and Greek, larger 8-bit codesets have been designed.
Multibyte character codes are required for alphabets of more than 256 characters, such as kanji, which consists of Japanese ideographs based on Chinese characters. Kanji has tens of thousands of characters, each of which is represented by two bytes. To ensure backward compatibility with ASCII, a multibyte codeset is a superset of the ASCII codeset and consists of a mixture of one- and two-byte characters.
For such languages, several encoding schemes have been defined. These encoding schemes provide a set of rules for parsing a byte stream into a group of coded characters.
1.2.2.1 Multibyte Encodings
Handling multibyte character encodings is a challenging task. It involves parsing multibyte character sequences, and in many cases requires conversions between multibyte characters and wide characters.
Understanding multibyte encoding schemes is easier when explained by means of a typical example. One of the earliest and probably biggest markets for multibyte character support is in Japan. Therefore, the following examples are based on encoding schemes for Japanese text processing.
In Japan, a single text message can be composed of characters from four different writing systems. Kanji has tens of thousands of characters, which are represented by pictures. Hiragana and katakana are syllabaries, each containing about 80 sounds, which are also represented as ideographs. The Roman characters include some 95 letters, digits, and punctuation marks.
Figure 1 gives an example of an encoded Japanese sentence composed of these four writing systems:
Figure 1. A Japanese sentence mixing four writing systems

The sentence means: "Encoding methods such as JIS can support texts that mix Japanese and English."
A number of Japanese character sets are common:
|
JIS C 6226-1978 |
JIS X 0208-1983 |
|
JIS X 0208-1990 |
JIS X 0212-1990 |
|
JIS-ROMAN |
ASCII |
There is no universally recognized multibyte encoding scheme for Japanese. Instead, we deal with the three common multibyte encoding schemes defined below:
|
JIS (Japanese Industrial Standard) |
|
Shift-JIS |
|
EUC (Extended UNIX Code) |
JIS Encoding
The JIS, or Japanese Industrial Standard, supports a number of standard Japanese character sets, some requiring one byte, others two. Escape sequences are required to shift between one- and two-byte modes.
Escape sequences, also referred to as shift sequences, are sequences of control characters. Control characters do not belong to any of the alphabets. They are artificial characters that do not have a visual representation. However, they are part of the encoding scheme, where they serve as separators between different character sets, and indicate a switch in the way a character sequence is interpreted. The use of the shift sequence is demonstrated in Figure 2.
Figure 2. An example of a Japanese text encoded in JIS
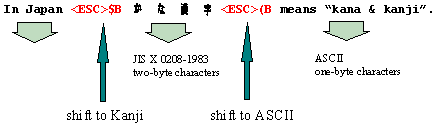
For encoding schemes containing shift sequences, like JIS, it is necessary to maintain a shift state while parsing a character sequence. In the example above, we are in some initial shift state at the start of the sequence. Here it is ASCII. Therefore, characters are assumed to be one-byte ASCII codes until the shift sequence <ESC>$B is seen. This switches us to two-byte mode, as defined by JIS X 0208-1983. The shift sequence <ESC>(B then switches us back to ASCII mode.
Encoding schemes that use shift state are not very efficient for internal storage or processing. Sometimes shift sequences require up to six bytes. Frequent switching between character sets in a file of strings could cause the number of bytes used in shift sequences to exceed the number of bytes used to represent the actual data!
Encodings containing shift sequences are used primarily as an external code, which allows information interchange between a program and the outside world.
Shift-JIS Encoding
Despite its name, Shift-JIS has nothing to do with shift sequences and states. In this encoding scheme, each byte is inspected to see if it is a one-byte character or the first byte of a two-byte character. This is determined by reserving a set of byte values for certain purposes. For example:
Any byte having a value in the range 0x21-7E is assumed to be a one-byte ASCII/JIS Roman character.
Any byte having a value in the range 0xA1-DF is assumed to be a one-byte half-width katakana character.
Any byte having a value in the range 0x81-9F or 0xE0-EF is assumed to be the first byte of a two-byte character from the set JIS X 0208-1990. The second byte must have a value in the range 0x40-7E or 0x80-FC.
While this encoding is more compact than JIS, it cannot represent as many characters as JIS. In fact, Shift-JIS cannot represent any characters in the supplemental character set JIS X 0212-1990, which contains more than 6,000 characters.
EUC Encoding
EUC is not peculiar to Japanese encoding. It was developed as a method for handling multiple character sets, Japanese or otherwise, within a single text stream.
The EUC encoding is much more extensible than Shift-JIS since it allows for characters containing more than two bytes. The encoding scheme used for Japanese characters is as follows:
Any byte having a value in the range 0x21-7E is assumed to be a one-byte ASCII/JIS Roman character.
Any byte having a value in the range 0xA1-FE is assumed to be the first byte of a two-byte character from the set JIS X0208-1990. The second byte must also have a value in that range.
Any byte having a value in the range 0x8E is assumed to be followed by a second byte with a value in the range 0xA1-DF, which represents a half-width katakana character.
Any byte having the value 0x8F is assumed to be followed by two more bytes with values in the range 0xA1-FE, which together represent a character from the set JIS X0212-1990.
The last two cases involve a prefix byte with values 0x8E and 0x8F, respectively. These bytes are somewhat like shift sequences in that they introduce a change in subsequent byte interpretation. However, unlike the shift sequences in JIS which introduce a sequence, these prefix bytes must precede every multibyte character, not just the first in a sequence. For this reason, each multibyte character encoded in this manner stands alone and EUC is not considered to involve shift states.
Uses of the Three Multibyte Encodings
The three multibyte encodings just described are typically used in separate areas:
JIS is the primary encoding method used for electronic transmission such as e-mail because it uses only 7 bits of each byte. This is required because some network paths strip the eighth bit from characters. Escape sequences are used to switch between one- and two-byte modes, as well as between different character sets.
Shift-JIS was invented by Microsoft and is used on MS-DOS-based machines. Each byte is inspected to see if it is a one-byte character or the first byte of a two-byte character. Shift-JIS does not support as many characters as JIS and EUC do.
EUC encoding is implemented as the internal code for most UNIX-based platforms. It allows for characters containing more than two bytes, and is much more extensible that Shift-JIS. EUC is a general method for handling multiple character sets. It is not peculiar to Japanese encoding.
1.2.2.2 Wide Characters
Multibyte encoding provides an efficient way to move characters around outside programs, and between programs and the outside world. Once inside a program, however, it is easier and more efficient to deal with characters that have the same size and format. We call these wide characters.
An example will illustrate how wide characters make text processing inside a program easier. Consider a filename string containing a directory path with adjacent names separated by a slash, like /CC/include/locale.h. To find the actual filename in a single-byte character string, we can start at the back of the string. When we find the first separator, we know where the filename starts. If the string contains multibyte characters, we scan from the front so we don't inspect bytes out of context. If the string contains wide characters, however, we can treat it like a single-byte character and scan from the back.
Conceptually, you can think of wide character sets as being extended ASCII or EBCDIC[3]; each unique character is assigned a distinct value. Since they are used as the counterpart to a multibyte encoding, wide character sets must allow representation of all characters that can be represented in a multibyte encoding as wide characters. As multibyte encodings support thousands of characters, wide characters are usually larger that one byte--typically two or four bytes. All characters in a wide character set are of equal size. The size of a wide character is not universally fixed, although this depends on the particular wide character set.
There are many wide character standards, including those shown below:
|
ISO 10646.UCS-2[4] |
16-bit characters |
|
ISO 10646.UCS-4 |
32-bit characters |
|
Unicode[5] |
16-bit characters |
The programming language C++ supports wide characters; their native type in C++ is called whar_t. The syntax for wide character constants and wide character strings is similar to that for ordinary, tiny character constants and strings:
|
L'a' is a wide character constant, and |
|
L"abc" is a wide character string. |
1.2.2.3 Conversion between Multibytes and Wide Characters
Since wide characters are usually used for internal representation of characters in a progam, and multibyte encodings are used for external representation, converting multibytes to wide characters is a common task during input/output operations. Input to and output from files is a typical example. The file will usually contain multibyte characters. When you read such a file, you convert these multibyte characters into wide characters that you store in an internal wide character buffer for further processing. When you write to a multibyte file, you have to convert the wide characters held internally into multibytes for storage on a external file. Figure 3 demonstrates graphically how this conversion during file input is done:
Figure 3. Conversion from a multibyte to a wide character encoding
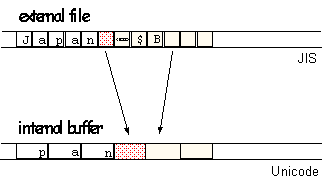
The conversion from a multibyte sequence into a wide character sequence requires expansion of one-byte characters into two- or four-byte wide characters. Escape sequences are eliminated. Multibytes that consist of two or more bytes are translated into their wide character equivalents.
1.2.3 Summary
Formatting and parsing of numbers, currency unit, dates, and time;
Handling different alphabets, their character classification, and collation sequences;
Converting codesets, including multibyte to wide character conversion;
Handling messages in different languages.
©Copyright 1996, Rogue Wave Software, Inc.